一个记录了生成式 AI 中的文生图、文生视频模型等不同技术重要时间点的发展史。 Fork 自 Fabian Mosele
最早的卷积神经网络之一,设计用于手写和机器打印字符识别。
包含超过1400万张图像的数据集,所有图像都有人工标注的内容描述。当时最大的图像数据集,推动了计算机视觉研究的发展。
在2012年ImageNet竞赛(ILSVRC12)中,这个卷积神经网络革新了图像分类的方式。
大规模目标检测、分割和描述数据集,包含超过20万张标注图像。
一个用于在两个对抗神经网络之间生成图像的机器学习框架。
谷歌在ILSVRC14上提出的卷积神经网络。
谷歌的计算机程序以其迷幻的视觉效果为特征。是可视化神经网络如何识别和生成图像模式的首个用例之一。
最早的文生图模型之一,是DRAW网络(深度递归注意力写入器)的扩展。该模型在微软COCO数据集上训练。
一个能够分离图像内容和风格并将不同的内容和风格结合的深度神经网络。
一个条件对抗网络,可以从特定类别的标签图生成图像。
最早基于生成对抗网络(GAN)的文生图模型之一,通过将工作负载分成两个独立的阶段生成256x256图像。
一种能够将图像内容更改为另一个类别的GAN类型。
最早基于生成对抗网络(GAN)的文生图模型之一。
一个能够生成多个类别图像的大规模GAN。
NVIDIA受风格迁移技术启发的GAN。首次生成的面孔看起来异常真实,通过thispersondoesnotexist.com/网站(现由StyleGAN2提供支持)变得流行。
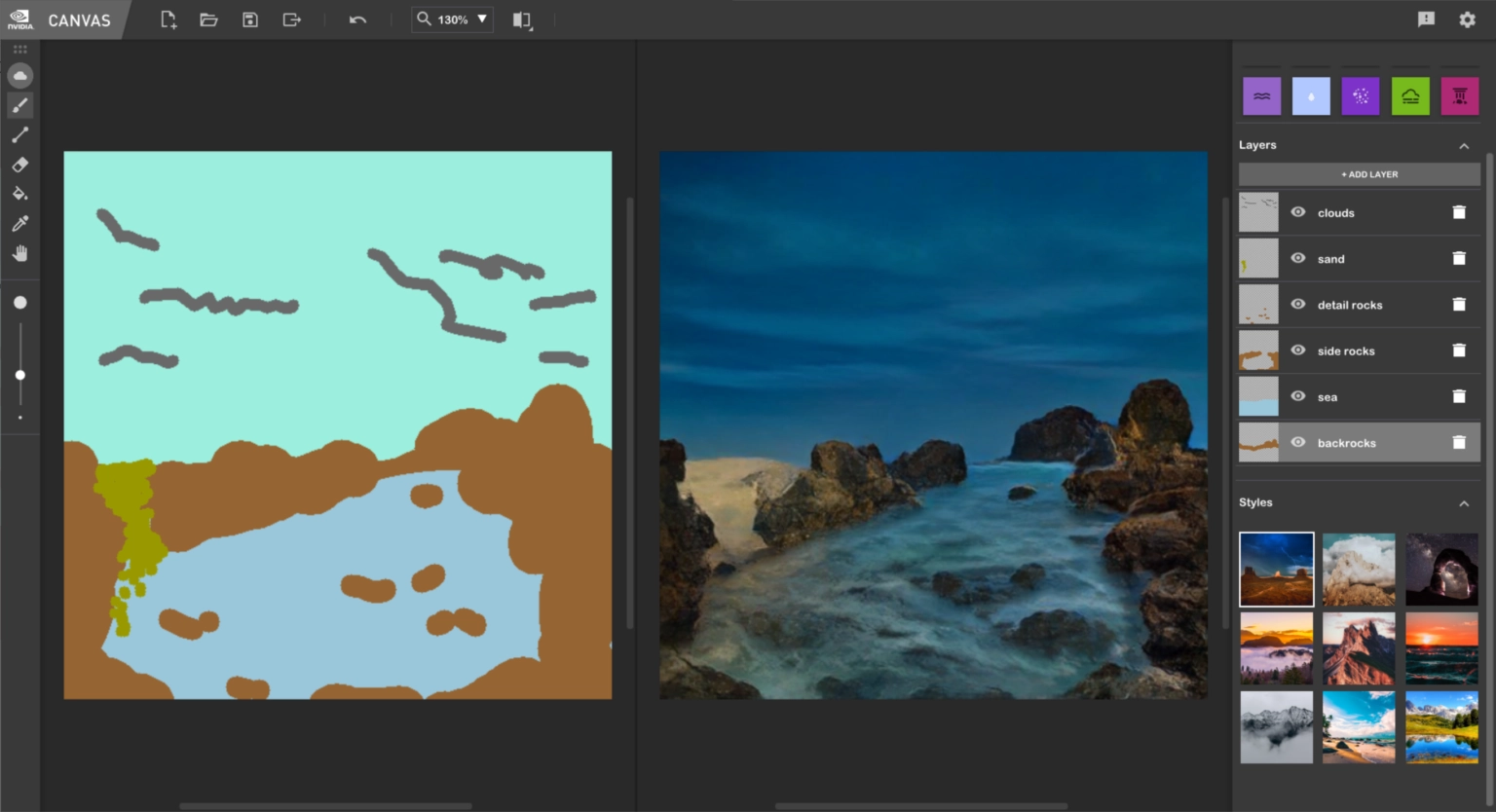
NVIDIA通过标签图生成真实景观的GAN。2021年发布的GauGAN2现由NVIDIA Canvas提供支持。
一个工具,能够在现实肖像或动漫面孔等类别中通过图像和特征参数进行杂交。由StyleGAN和BigGAN提供支持。
NVIDIA更新版StyleGAN。可以在任何数据集上训练,但最知名的是thispersondoesnotexist.com/。
对比语言-图像预训练是一个在图像和文本关系上训练的神经网络。这个模型对公众开放,开启了文生图模型的文艺复兴。
OpenAI的首个文生图模型,是其CLIP模型的首次实现。由于代码未发布,这为各种试图模仿它的开源模型铺平了道路。
首个使用CLIP的开源模型,与SIREN(正弦表示网络)配对。由Ryan Murdock(@advadnoun)创建。
Ryan Murdock(@advadnoun)的Colab笔记本,将CLIP连接到BigGAN。第一个使用CLIP从文本生成图像的流行笔记本。
Vadim Epstein(@eps969)的Colab笔记本,将CLIP连接到Lucent库。
Ryan Murdock(@advadnoun)的Colab笔记本,使用CLIP和DALLE的解码器生成图像。
Katherine Crowson(@RiversHaveWings)的Colab笔记本,使文生图模型普及。受Big Sleep启发,这个笔记本是普通用户可以尝试这些工具的最早实例之一。
类似DALL·E的简体中文文生图模型。
虽然是指与CLIP一起工作的扩散模型的通用术语,但这是第一个CLIP引导的扩散模型。由Katherine Crowson(@RiversHaveWings)创建。
一个开放的数据集,包含2014年至2021年间随机网页的文本图像对,通过OpenAI的CLIP过滤。
从Crowson的CLIP引导扩散模型演变而来,Disco Diffusion是一个流行的文生图模型,可以创建画风图像。
由@RiversHaveWings和@jd_pressman创建的扩散模型。
一个俄罗斯版的DALLE,在架构模型上有所不同。使用俄罗斯语言版本的CLIP,ruCLIP进行训练。
一个由sportsracer48创建的基于VQGAN的笔记本,在Patreon上作为封闭测试版提供。基于Katherine Crowson的笔记本,Pytti 5以创建迷幻动画而闻名。
GauGAN的续集,现称为NVIDIA Canvas。可以从更细粒度的标签图生成景观。
微软的多模态文生图和文生视频模型。
由CompVis开发的文生图模型。
由OpenAI开发的扩散模型。它将成为DALLE 2架构的基础之一。
先前为封闭测试版,Midjourney现为开放测试版文生图模型,通过其Discord服务器的订阅模式工作。
OpenAI最大规模的文生图模型发布。可以通过付费积分系统生成。
正如名字所暗示的,这个笔记本结合了两个扩散模型的优势。潜在扩散在连贯性方面表现良好,而Disco Diffusion在艺术性方面更好,结合后它们创造了一个中间地带。
由Boris Dayma开发的文生图模型,试图成为DALL·E 2的开源版本。因模因在AI社区之外获得人气,因与OpenAI的法律纠纷后更名为Craiyon。
CogView的继任者,这个文生图模型支持中文和英语。
谷歌的DALL·E竞争对手,虽然尚未向公众开放。
LAION最大的开放数据集,包含58.5亿个CLIP过滤的图像-文本对,比其前身LAION-400M大14倍。
由CogView的创建者开发,CogVideo是一个可以生成短GIF的中文文生视频模型。
谷歌的文生图模型,是OpenAI的DALL·E的竞争对手。
更强大的GauGAN版本。Meta的带有标签图的文生图模型。
微软的自回归视觉合成预训练模型,用于文生图和文生视频。
Stability AI和CompVis开发的开源文生图模型。
谷歌通过微调文生图模型输出特定连贯对象。
Meta的文生视频模型。
一个用于从文本生成视频的模型,提示可以随时间变化,视频可以长达数分钟。
谷歌的文生视频模型,是他们的T2I模型Imagen的继任者。
百度的文生图模型。参数少于DALLE或Stable Diffusion,但在空间理解和颜色匹配方面表现出色。
Midjourney和Spellbrush合作的漫画/动漫图像模型。使用修改后的Midjourney模型。
一个通过Stable Diffusion和GPT-3生成的数据训练的模型,可以根据人类指令编辑图像。
Stable Diffusion的更新版本,与v1相比一切都是开源的。v1使用OpenAI的CLIP,v2使用由LAION开发并由Stability AI支持的OpenCLIP。
一个微调在可翻译为音频文件的频谱图像上的文生图Stable Diffusion模型。
一个使用LLM的令牌潜在空间而不是扩散模型的文生图Transformer模型。
RunwayML的video2video工具,通过文本或图像提示用生成视觉效果编辑视频。其公开发布在2023年3月27日。3月20日宣布了Gen-2,一个基于同一论文的文生视频工具。
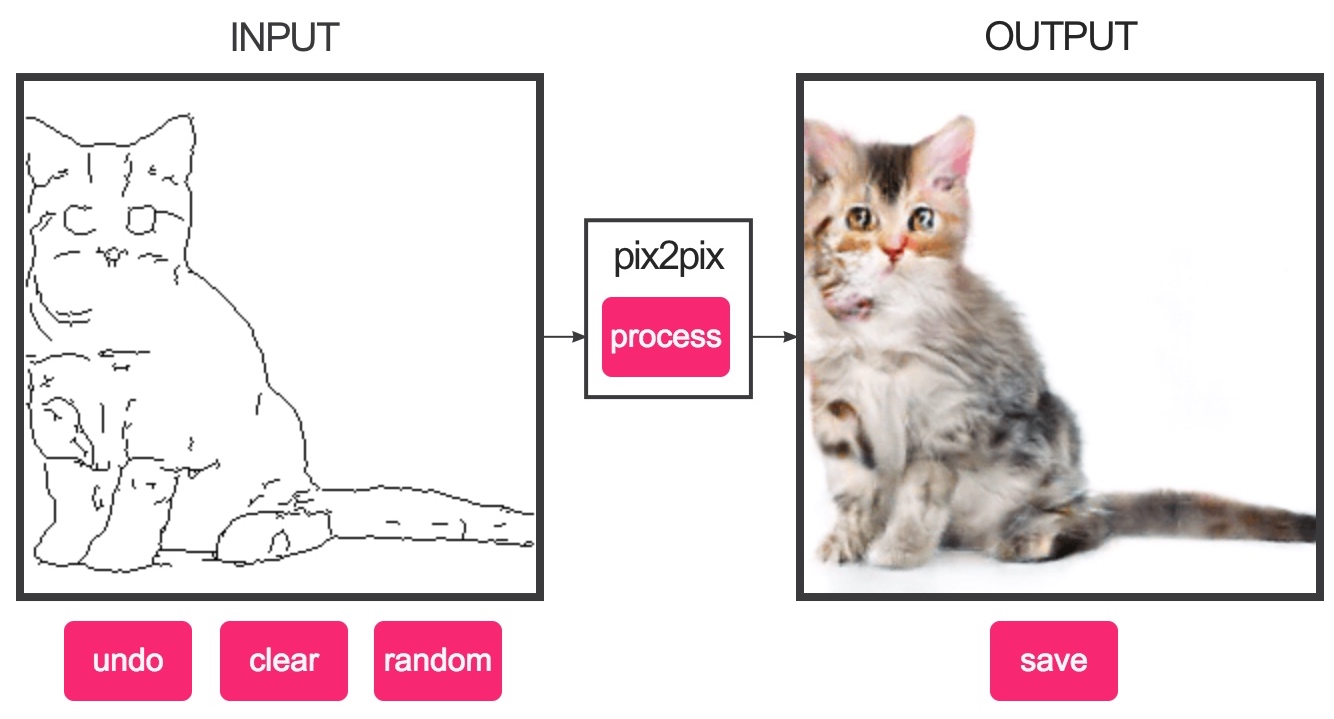
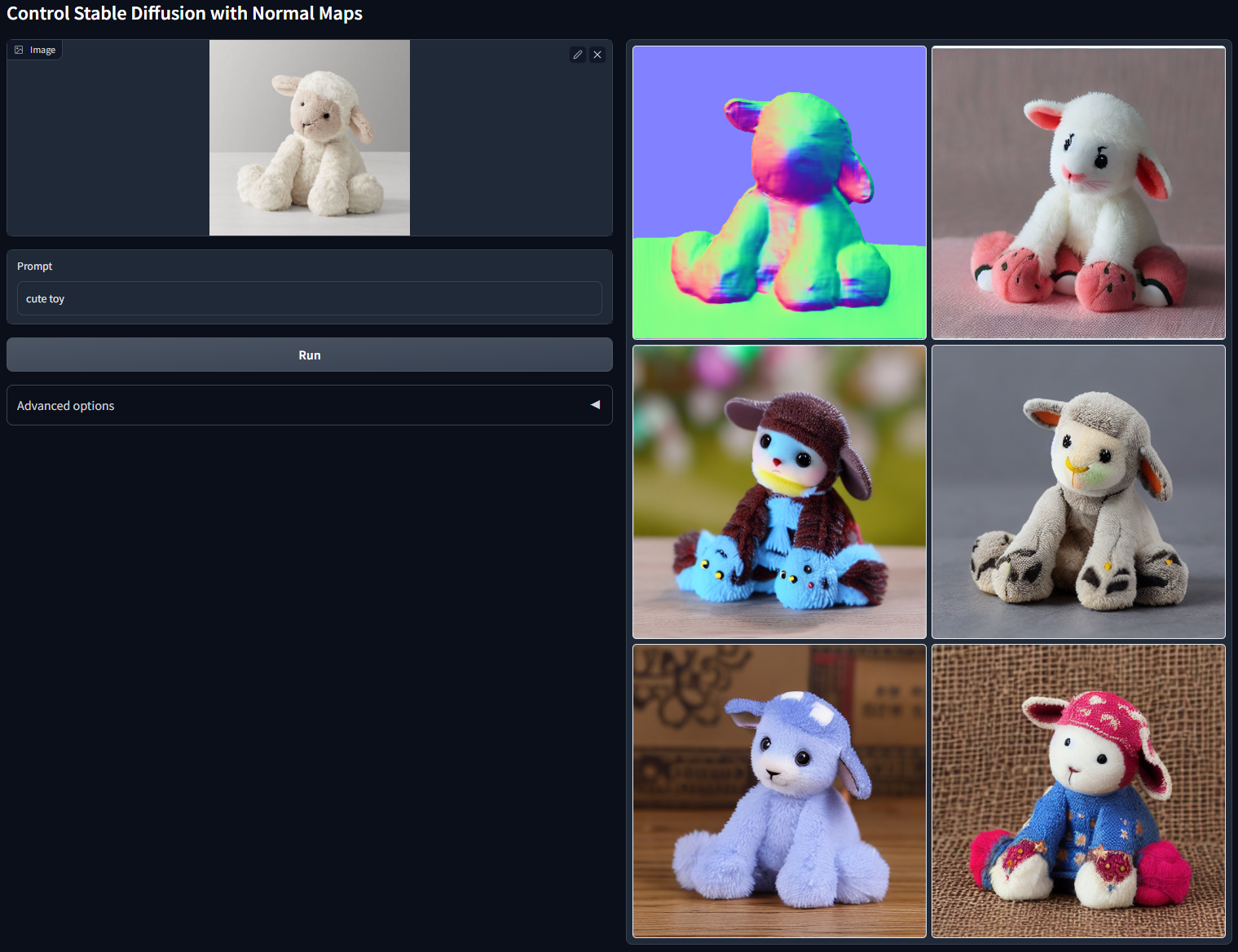
一种用于通过不同技术控制扩散模型的神经网络结构。它允许通过img2img对图像结构进行更多控制。不同技术包括边缘检测、深度图、分割图和人体姿态。
一个通过英语提示生成2秒视频的文生视频模型。由同名的中国模型即服务库发布,由阿里巴巴拥有。
RunwayML的文生视频工具。基于与一个月前发布的video2video工具Gen-1相同的论文。
Firefly是Adobe开发的生成文本到图像工具系列。
一个多模态文生视频模型,通过不同的扩散模型架构生成长视频。
Midjourney发布的第五版。
一个生成成本更低的文生图模型,因为其高度压缩的潜在空间(名字很搞笑)。
一个基于Modelscope的开源文生视频模型。不同版本可用,质量和大小不断增加。由Spencer Sterling开发。
一个文生视频模型,第一个开源生成1024x576视频的模型。由Camenduru开发,以Modelscope为基础模型。
通过Discord服务器运行的文生视频模型。Pika 1.0于2023年11月28日宣布拥有自己的网站。
通过Stable Diffusion模型生成视频的文生视频模型。
Stability AI开发的更大规模的Stable Diffusion文生图模型,这次训练了1024像素的图像而不是512像素。
OpenAI开发的第三代DALLE。由于改进了数据集图像的描述,这个模型对文本有更细致的理解,并且能够更好地遵循提示中的描述。
Showlab 在新加坡国立大学开发的文生视频模型,具有更高效的GPU使用率。
一个替代潜在扩散模型的文生图模型,能够在几个推理步骤中生成高质量的图像。一个流行的应用是LCM LoRAs,发布于2023年11月9日,可以加速Stable Diffusion模型中的生成过程。
一个视频生成模型,将图像的主体转移到视频的人物主体的动作上。
谷歌的文生图模型。这个是首个Imagen的继任者,用于各种谷歌生成服务,如Gemini。
Midjourney发布的第六版。这个版本更善于处理详细的提示。
谷歌的生成视频扩散模型。
ByteDance开发的用于视频扩散模型的运动控制插件。通过框定不同元素的运动的边界框,可以详细控制生成视频的运动。
OpenAI开发的生成视频扩散模型,能够生成一分钟的生成视频,在现实主义和一致性方面超越了所有前代模型。目前仅对少数人开放。
Snapchat开发的文生视频模型。公司在图像/视频生成领域的首次尝试。
Stability AI开发的最受欢迎的开源图像生成模型Stable Diffusion的第三代。虽然模型尚未发布,但已开放早期预览候补名单。
谷歌的第三代文生图模型Imagen,可在其ImageFX网站上使用。
谷歌的文生视频模型,能够从文本、图像和视频输入生成视频。目前仅通过加入候补名单可用。
生成动画插帧的生成模型,能够生成两帧或多帧图像之间的插帧。与其他插帧模型不同,这是由生成视频模型驱动的,能够预测更准确的运动。它还可以为草图上色。
快手开发的文生视频模型,第一个严肃的Sora竞争对手,能够生成长达2分钟的视频。此外可以通过OpenPose骨架输入提示(主要用于舞蹈)。在其应用内加入候补名单的用户可用。
Luma Labs开发的文生视频模型,通过文本或图像提示生成视频。通过其网站向公众开放。
Runway开发的生成视频模型,继Gen-1和Gen-2之后。其两个前辈的改进版本,Gen-3 Alpha承诺可以自定义模型以进行风格控制。仅对其网站上的付费用户开放。
Midjourney 第 6 版的小升级,图像质量、处理速度和个性化体验的显著提升。
生数科技携手清华大学研发出的视频生成模型,早在4月28号时就公布了演示,号称国内第一个类 Sora 模型,上线后免费用户支持生成4秒视频
FLUX.1由前 SAI 开发者组成的Black Forest Labs团队推出首个文本到图像生成模型。现有三个不同版本:Pro,效果最好只支持API调用;Dev,开放权重模型,可用于非商业应用;Schnell,速度最快,基于 Apache 2.0
CogVideoX 是由智谱开源的与其清影模型同源的文生视频系列模型,目前只开源了 2B 模型,能生成 6 秒长,8帧/秒的视频
由创业公司MiniMax开发的文本到视频模型,可在其网站上使用。相比之前的视频生成模型有明显升级,在灵活性和提示词遵循方面表现出色。
Adobe开发的文本到视频模型。目前尚未发布,只能通过加入等待列表。这是一个商业安全的模型,不同之处在于它还能生成与图像在风格上相似的视频,将来还会集成到Adobe Premiere中。
Meta开发的视频生成模型,可从文本创建视频、编辑现有视频,并通过人脸输入将人物放入生成的场景中。目前尚未发布。
基于Flow Matching的开源自回归视频生成方法。仅在开源数据集上训练。
基于实时用户输入生成下一帧的交互式视频生成模型。演示版本在Minecraft游戏视频和键盘输入上训练。首个此类开源交互式实时视频生成模型。
开源视频生成模型,可在768x512分辨率下生成24 FPS视频,他们声称生成速度比观看视频的时间还要快。
腾讯发布的开源视频生成模型,是该公司首个此类模型。生成过程较长,但迄今为止拥有最佳的开源视频生成效果。
OpenAI早在2月就宣布的视频生成扩散模型。迄今为止最受期待的视觉生成模型,通过20美元或200美元订阅提供。发布版本是之前模型的turbo版本。虽然与大多数其他视频模型类似,但其故事板界面是首创,允许对一个动作接一个动作进行关键帧设置,并无缝融合两个视频。
Google DeepMind开发的视频生成模型,在质量、提示词遵循和因果关系方面超越其他视频模型。目前仅通过VideoFX的封闭等待列表或在Fal等不同网站付费使用。
字节跳动开发的专门制作逼真角色唇同步和动作的视频生成模型。允许图像和音频输入,该模型致力于生成自然的人类唇同步和相应的身体动作。
Meta开发的框架,为任何视频生成模型注入强烈的运动先验,通过增强模型运动的真实感来提升效果。
通过在高质量影视片段大数据集上微调Hunyuan视频模型创建的视频生成模型。
Wan2.1,原名WanX,是阿里巴巴发布的开源视频生成模型。通过LoRA微调实现的高度个性化视频模型。
Runway视频模型的第四代。相比前代产品,具有更强的提示词遵循能力和运动灵活性。与Runway的图像生成器Frames结合使用,现在可以使用参考图像来组合和生成新视频。
Google DeepMind开发的视频生成模型,还可以原生生成声音和语音。首个具备这些一体化功能的模型,Veo 3允许使用图像参考生成视频,可在Google的服务如Flow和Gemini聊天界面中使用。
字节跳动开发的视频生成模型,据说具有与Veo 3相同的功能,但生成成本更低。一个显著特点是可以轻松创建多镜头生成。
由Moonvalley和Asteria Film开发的仅使用授权数据训练的生成视频模型。首批不使用未经同意数据收集进行训练的视频模型之一。作为封闭模型,它具有多种控制功能,如姿态控制、风格转换、图像参考和起始-结束帧。仅通过其付费计划提供。该模型之前在3月曾预告,7月正式发布。
Wan2.2,阿里巴巴发布的开源视频生成模型,是 Wan 基础视频模型的重大升级。